
{kind=link}
मेटा ने अपने एआई योजनाओं के साथ एक और कदम आगे बढ़ाया है, इसके लामा 4 एआई मॉडल के लॉन्च के साथ, जो परीक्षण में, अपने प्रतिद्वंद्वियों की तुलना में लगभग सभी मोर्चों पर बेहतर प्रदर्शन प्रदान करने के लिए साबित हुआ है।
खैर, कम से कम उन परिणामों के आधार पर जो मेटा को जारी करने के लिए चुना गया था, लेकिन हम उस पर पहुंचेंगे।
सबसे पहले, मेटा ने चार नए मॉडलों की घोषणा की जिसमें पिछले लामा मॉडल की तुलना में बहुत बड़ा व्यवस्थित प्रशिक्षण और पैरामीटर अनुमान शामिल हैं।

मेटा के चार (हाँ, चार, अंतिम एक इस छवि में चित्रित नहीं किया गया है) नए लामा मॉडल हैं:
- Llama 4 स्काउट तुरंत सबसे तेज़ छोटा मॉडल उपलब्ध हो जाता है, और इसे एकल GPU पर चलाने के लिए डिज़ाइन किया गया है। स्काउट में 17 बिलियन पैरामीटर और 16 विशेषज्ञ शामिल हैं, जो सिस्टम को प्रत्येक क्वेरी की प्रकृति के आधार पर अपनी प्रतिक्रियाओं को अनुकूलित करने में सक्षम बनाता है।
- Llama 4 Maverick में 17 बिलियन पैरामीटर संसाधन भी शामिल है, लेकिन इसमें 128 विशेषज्ञ भी शामिल हैं। “विशेषज्ञों” का उपयोग इसका मतलब है कि कुल मापदंडों का केवल एक सबसेट प्रत्येक क्वेरी के लिए सक्रिय है, जिससे मॉडल की सेवा को कम करके मॉडल दक्षता में सुधार होता है। इसका मतलब है कि इन मॉडलों का उपयोग करने वाले डेवलपर्स कम गणना के साथ समान परिणाम प्राप्त कर सकते हैं।
- Llama 4 Behemoth में 2 ट्रिलियन से अधिक पैरामीटर शामिल हैं, जिससे यह वर्तमान में उपलब्ध सबसे बड़ी प्रणाली है। कम से कम सिद्धांत रूप में, उन्नत सीखने और अनुमान के साथ प्रश्नों को समझने और प्रतिक्रिया करने में सक्षम होने के लिए इसे और अधिक क्षमता देता है।
- Llama 4 रीजनिंग अंतिम मॉडल है, जिसे मेटा ने अभी तक बहुत अधिक जानकारी साझा नहीं की है।
इनमें से प्रत्येक मॉडल एक अलग उद्देश्य का कार्य करता है, मेटा रिलीज करने वाले चर विकल्पों के साथ जो कम या अधिक शक्तिशाली प्रणालियों के साथ चलाया जा सकता है। इसलिए यदि आप अपनी खुद की एआई सिस्टम का निर्माण करना चाहते हैं, तो आप लामा स्काउट का उपयोग कर सकते हैं, जो सबसे छोटे मॉडल हैं, जो एक एकल जीपीयू पर चल सकते हैं।
तो यह सब आम आदमी की शर्तों में क्या है?
स्पष्ट करने के लिए, इनमें से प्रत्येक सिस्टम “मापदंडों” की एक सीमा पर बनाया गया है जो मेटा की विकास टीम द्वारा व्यवस्थित तर्क में सुधार करने के लिए स्थापित किया गया है। वे पैरामीटर स्वयं डेटासेट नहीं हैं (जो कि भाषा मॉडल है), लेकिन उस डेटा को समझने के लिए सिस्टम में निर्मित नियंत्रण और संकेत की मात्रा है जिसे वह देख रहा है।
तो 17 बिलियन मापदंडों वाली एक प्रणाली में आदर्श रूप से कम मापदंडों के साथ एक से बेहतर तर्क प्रक्रिया होगी, क्योंकि यह प्रत्येक क्वेरी के अधिक पहलुओं के बारे में सवाल पूछ रहा है, और उस संदर्भ के आधार पर जवाब दे रहा है।
उदाहरण के लिए, यदि आपके पास एक चार पैरामीटर मॉडल था, तो यह मूल रूप से पूछ रहा होगा कि “कौन, क्या, कहाँ, और कब”, प्रत्येक अतिरिक्त पैरामीटर के साथ अधिक से अधिक बारीकियों को जोड़ रहा है। Google खोज, एक तुलना के रूप में, प्रत्येक क्वेरी के लिए 200 से अधिक “रैंकिंग सिग्नल” का उपयोग करता है, जो आप दर्ज करते हैं, ताकि आपको अधिक सटीक परिणाम प्रदान किया जा सके।
तो आप कल्पना कर सकते हैं कि 17 बिलियन पैरामीटर प्रक्रिया का विस्तार कैसे होगा।
और लामा 4 के पैरामीटर मेटा के पिछले मॉडल के दायरे से दोगुना से अधिक हैं।
तुलना के लिए:
इसलिए, जैसा कि आप देख सकते हैं, समय के साथ, अधिक प्रश्न पूछने के लिए अधिक सिस्टम लॉजिक में मेटा की इमारत, और प्रत्येक अनुरोध के संदर्भ में आगे खुदाई करें, जो तब इस प्रक्रिया के आधार पर अधिक प्रासंगिक, सटीक प्रतिक्रियाएं प्रदान करनी चाहिए।
मेटा के “विशेषज्ञ”, इस बीच, लामा 4 के भीतर एक नया तत्व है, और व्यवस्थित नियंत्रण हैं जो परिभाषित करते हैं कि उन मापदंडों में से कौन सा लागू किया जाना चाहिए, या नहीं, प्रत्येक क्वेरी में। यह गणना समय को कम करता है, जबकि अभी भी सटीकता बनाए रखता है, जो यह सुनिश्चित करना चाहिए कि मेटा के लामा मॉडल का उपयोग करने वाली बाहरी परियोजनाएं उन्हें कम कल्पना प्रणालियों पर चलाने में सक्षम होंगी।
क्योंकि शाब्दिक रूप से किसी के पास वह क्षमता नहीं है जो मेटा इस मोर्चे पर करती है।
मेटा वर्तमान में आसपास है 350,000 NVIDIA H100 चिप्स अपनी एआई परियोजनाओं को शक्ति प्रदान करनाअधिक ऑनलाइन आने के साथ, क्योंकि यह अपने डेटा सेंटर क्षमता का विस्तार करना जारी रखता है, जबकि यह अपने स्वयं के एआई चिप्स को भी विकसित कर रहा है जो आगे भी इस पर निर्माण करने के लिए तैयार दिखते हैं।
Openai कथित तौर पर है ऑपरेशन में लगभग 200k H100sजबकि XAI का “कोलोसस” सुपर सेंटर वर्तमान में चल रहा है 200k H100 चिप्स भी।
इसलिए मेटा अब अपने प्रतिद्वंद्वियों की क्षमता को दोगुना करने की संभावना है, हालांकि Google और Apple भी उसी के लिए अपने स्वयं के दृष्टिकोण विकसित कर रहे हैं।
लेकिन मूर्त, उपलब्ध गणना और संसाधनों के संदर्भ में, मेटा स्पष्ट रूप से लीड में बहुत स्पष्ट है, इसके नवीनतम बीहमोथ मॉडल के साथ समग्र प्रदर्शन के मामले में अन्य सभी एआई परियोजनाओं को पानी से बाहर उड़ाने के लिए सेट किया गया है।
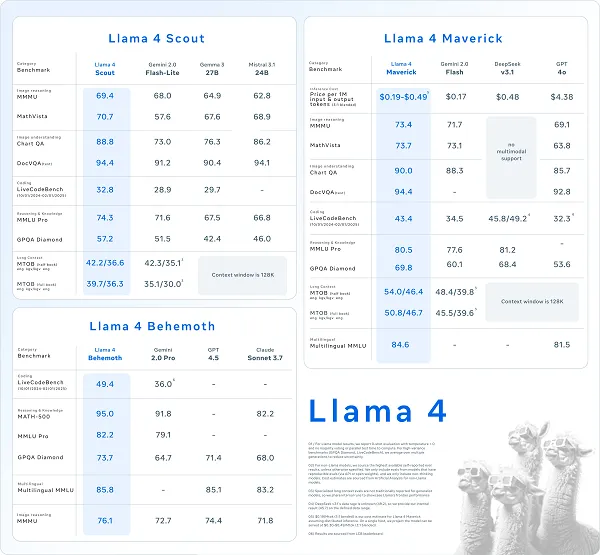
आप इस चार्ट में प्रमुख एआई परियोजनाओं के बीच तुलनात्मक प्रदर्शन की तुलना देख सकते हैं, हालांकि कुछ सवालों को मेटा की परीक्षण प्रक्रिया की सटीकता और प्रयोज्यता के रूप में भी उठाया गया है, और इसके लामा मॉडल से मेल खाने के लिए चुना गया बेंचमार्क।
यह परीक्षण में बाहर आ जाएगा, और उपयोगकर्ता के अनुभव में किसी भी तरह से, लेकिन यह भी ध्यान देने योग्य है कि लामा 4 द्वारा उत्पादित सभी परिणाम उतने ही मन-उड़ा रहे हैं जितना मेटा का सुझाव लगता है।
लेकिन कुल मिलाकर, यह सभी मोर्चों पर बेहतर परिणाम दे रहा है, जबकि मेटा यह भी कहती है कि कम एंट्री मॉडल प्रतियोगिता की तुलना में एक्सेस करने के लिए सस्ता है, और बेहतर है।
यह महत्वपूर्ण है, क्योंकि मेटा बाहरी एआई परियोजनाओं में उपयोग के लिए इन सभी मॉडलों को भी सोर्सिंग करता है, जो तीसरे पक्ष के डेवलपर्स को अलग-अलग उद्देश्य के लिए नए, समर्पित एआई मॉडल बनाने में सक्षम बना सकता है।
यह किसी भी तरह से एक महत्वपूर्ण अपग्रेड है, जो एआई विकास के लिए ढेर के शीर्ष पर मेटा लगाने के लिए खड़ा है, जबकि बाहरी डेवलपर्स को अपने लामा मॉडल का उपयोग करने में सक्षम बनाता है, यह भी मेटा को कई एआई परियोजनाओं के लिए प्रमुख लोड-असर नींव बनाने के लिए खड़ा है।
पहले से ही, लिंक्डइन और Pinterest कई प्रणालियों में से हैं जो मेटा के लामा मॉडल को शामिल कर रहे हैं, और जैसा कि यह बेहतर सिस्टम का निर्माण करना जारी रखता है, ऐसा लगता है कि मेटा एआई दौड़ में जीत रही है। क्योंकि ये सभी सिस्टम इन मॉडलों पर निर्भर हो रहे हैं, और जैसा कि वे करते हैं, जो मेटा पर उनकी निर्भरता को बढ़ाता है, और इसके चल रहे लामा अपडेट, उनके विकास को शक्ति देने के लिए।
लेकिन फिर से, इस की प्रासंगिकता को सरल बनाना कठिन है, एआई विकास की जटिल प्रकृति को देखते हुए, और ऐसी प्रक्रियाएं जो इस तरह को चलाने के लिए आवश्यक हैं।
नियमित उपयोगकर्ताओं के लिए, इस अपडेट का सबसे प्रासंगिक हिस्सा मेटा के अपने एआई चैटबॉट और जेनरेशन मॉडल का बेहतर प्रदर्शन होगा।
मेटा अपने लामा 4 मॉडल को अपने इन-ऐप चैटबॉट में भी एकीकृत कर रहा है, जिसे आप फेसबुक, व्हाट्सएप, इंस्टाग्राम और मैसेंजर के माध्यम से एक्सेस कर सकते हैं। अपडेटेड सिस्टम प्रोसेसिंग मेटा के विज्ञापन लक्ष्यीकरण मॉडल, इसके विज्ञापन पीढ़ी सिस्टम, इसके एल्गोरिथम मॉडल, आदि का भी हिस्सा बन जाएगा।
मूल रूप से, मेटा के ऐप्स का हर पहलू जो एआई का उपयोग करता है, अब उनके आकलन के भीतर अधिक तार्किक मापदंडों का उपयोग करके होशियार हो जाएगा, जिसके परिणामस्वरूप अधिक सटीक उत्तर, बेहतर छवि पीढ़ियों और बेहतर विज्ञापन प्रदर्शन में सुधार होना चाहिए।
यह पूरी तरह से निर्धारित करना मुश्किल है कि केस-बाय-केस के आधार पर इसका क्या मतलब होगा, क्योंकि व्यक्तिगत परिणाम अलग-अलग हो सकते हैं, लेकिन मैं मेटा के एडवांटेज+ विज्ञापन विकल्पों पर विचार करने का सुझाव दूंगा, यह देखने के लिए कि इसका प्रदर्शन कितना अच्छा हो गया है।
मेटा आने वाले हफ्तों में अपने नवीनतम Llama 4 मॉडल को एकीकृत करेगा, इस रिलीज़ में अभी भी अधिक उन्नयन आ रहा है।