
बड़े भाषा मॉडल (एलएलएम) ने स्पष्ट रूप से संरचित तर्क के निशान पर प्रशिक्षित होने पर महत्वपूर्ण सुधार दिखाए हैं, जिससे उन्हें गणितीय समीकरणों को हल करने, तार्किक निष्कर्षों को हल करने और मल्टीस्टेप प्लानिंग कार्यों को नेविगेट करने की अनुमति मिलती है। हालांकि, इन लंबी तर्क के निशान को संसाधित करने के लिए आवश्यक कम्प्यूटेशनल संसाधनों में पर्याप्त है। शोधकर्ता इन मॉडलों की प्रभावशीलता को बनाए रखते हुए दक्षता बढ़ाने के तरीकों का पता लगाना जारी रखते हैं।
एलएलएम तर्क में प्राथमिक चुनौतियों में से एक प्रशिक्षण और अनुमान से जुड़ी उच्च कम्प्यूटेशनल लागत है। जब मॉडल प्राकृतिक भाषा में चरण-दर-चरण तर्क के निशान को संसाधित करते हैं, तो पाठ का अधिकांश उपयोग तर्क में योगदान करने के बजाय सुसंगतता को बनाए रखने के लिए किया जाता है। यह अक्षम मेमोरी उपयोग और प्रसंस्करण समय में वृद्धि की ओर जाता है। वर्तमान तरीके महत्वपूर्ण जानकारी खोए बिना संपीड़ित अभ्यावेदन में तर्क के कदमों को अमूर्त करके इस मुद्दे को कम करना चाहते हैं। इन प्रयासों के बावजूद, ऐसे मॉडल जो निरंतर अव्यक्त स्थान या बहु-चरण प्रशिक्षण के माध्यम से तर्क के निशान को आंतरिक करने का प्रयास करते हैं, वे अक्सर पूर्ण तर्क विवरण के साथ प्रशिक्षित लोगों की तुलना में बदतर प्रदर्शन करते हैं।
मौजूदा समाधानों ने मध्यवर्ती चरणों को संपीड़ित करके तर्क के निशान में अतिरेक को कम करने का लक्ष्य रखा है। कुछ दृष्टिकोण निरंतर अव्यक्त अभ्यावेदन का उपयोग करते हैं, जबकि अन्य में तर्क अनुक्रमों के पुनरावृत्ति कटौती शामिल होती है। हालांकि, इन तरीकों को जटिल प्रशिक्षण प्रक्रियाओं की आवश्यकता होती है और स्पष्ट पाठ तर्क के तुलनीय प्रदर्शन को बनाए रखने में विफल रहते हैं। शोधकर्ताओं ने एक वैकल्पिक दृष्टिकोण की मांग की है जो तर्क क्षमताओं को संरक्षित करते हुए कम्प्यूटेशनल मांगों को कम करता है। इसे संबोधित करने के लिए, उन्होंने एक ऐसी विधि पेश की है, जो अव्यक्त असतत टोकन के साथ तर्क प्रक्रिया के कुछ हिस्सों को बदल देती है, सटीकता का त्याग किए बिना बेहतर दक्षता प्राप्त करती है।

मेटा एआई और यूसी बर्कले की एक शोध टीम ने एक उपन्यास तकनीक का प्रस्ताव दिया जो एलएलएम तर्क में असतत अव्यक्त टोकन को एकीकृत करता है। वे स्टेपवाइज रीजनिंग प्रक्रिया के एक हिस्से को कॉम्पैक्ट अभ्यावेदन में परिवर्तित करने के लिए एक वेक्टर-क्वांटिक वैरिएशनल ऑटोएन्कोडर (VQ-VAE) को नियुक्त करते हैं। विधि में पाठ के रूप में बाद के चरणों को बनाए रखते हुए अव्यक्त सार के साथ प्रारंभिक तर्क चरणों को बदलना शामिल है। यह हाइब्रिड प्रतिनिधित्व सुनिश्चित करता है कि मॉडल तर्क अनुक्रमों की टोकन लंबाई को कम करते हुए व्याख्याता बनाए रखता है। प्रमुख नवाचार अव्यक्त और पाठ टोकन का यादृच्छिक मिश्रण है, जो मॉडल को व्यापक रूप से बिना किसी रिट्रेनिंग के नए तर्क संरचनाओं के लिए मूल रूप से अनुकूलित करने में सक्षम बनाता है।
शोधकर्ताओं ने एक प्रशिक्षण रणनीति विकसित की, जिसमें एलएलएम तर्क के निशान में अव्यक्त टोकन शामिल हैं। प्रशिक्षण के दौरान, तर्क के चरणों की एक नियंत्रित संख्या को उनके संबंधित अव्यक्त अभ्यावेदन के साथ बदल दिया जाता है, यह सुनिश्चित करते हुए कि मॉडल अमूर्त और स्पष्ट तर्क संरचनाओं दोनों की व्याख्या करना सीखता है। अव्यक्त टोकन प्रतिस्थापन का यादृच्छिककरण मॉडल की सामान्यीकरण क्षमता में सुधार करते हुए विभिन्न समस्याओं के प्रकारों में अनुकूलनशीलता की अनुमति देता है। पाठीय तर्क चरणों की संख्या को सीमित करने से इनपुट आकार को कम कर दिया जाता है, जिससे तर्क प्रदर्शन को बनाए रखते हुए LLMs अधिक कम्प्यूटेशनल रूप से कुशल हो जाते हैं। इसके अलावा, शोधकर्ताओं ने यह सुनिश्चित किया कि नए पेश किए गए अव्यक्त टोकन सहित विस्तारित शब्दावली को प्रमुख संशोधनों की आवश्यकता के बिना मॉडल में मूल रूप से एकीकृत किया जा सकता है।
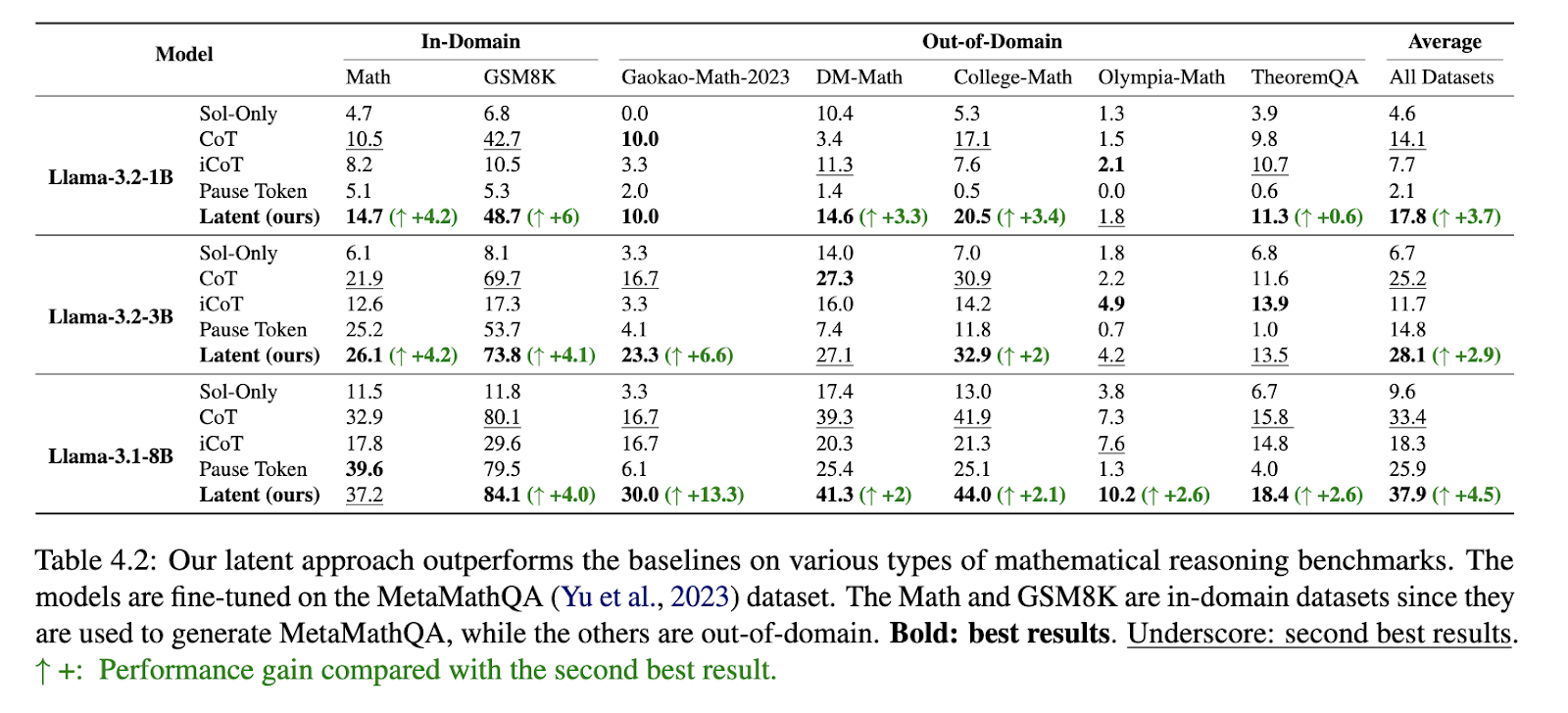
प्रस्तावित विधि ने विभिन्न बेंचमार्क में महत्वपूर्ण प्रदर्शन सुधारों का प्रदर्शन किया। गणितीय तर्क कार्यों पर लागू होने पर दृष्टिकोण ने पारंपरिक चेन-ऑफ-थॉट (COT) मॉडल को बेहतर बनाया। गणित डेटासेट पर, इसने पिछले सर्वश्रेष्ठ प्रदर्शन करने वाले तरीकों पर 4.2% सुधार प्राप्त किया। GSM8K बेंचमार्क में, दृष्टिकोण ने 4.1% की लाभ प्राप्त की, जबकि ताजा-गोकाओ-माथ -2023 डेटासेट में, इसने मौजूदा मॉडल को 13.3% से बेहतर बनाया। तर्क ट्रेस की लंबाई में कमी समान रूप से उल्लेखनीय थी, जिसकी औसत 17%की औसत कमी थी, जिसके परिणामस्वरूप तेजी से समय और कम मेमोरी की खपत हुई। ProntoQA और ProSQA जैसे तार्किक तर्क डेटासेट पर मूल्यांकन ने क्रमशः 1.2% और 18.7% की सटीकता में सुधार के साथ दृष्टिकोण की प्रभावशीलता को और अधिक मान्य किया। मॉडल ने सरल तर्क कार्यों पर 100% सटीकता हासिल की, कुशल तार्किक कटौती के लिए इसकी क्षमता का प्रदर्शन किया।
अव्यक्त टोकन की शुरूआत ने सटीकता से समझौता किए बिना एलएलएम तर्क को अनुकूलित करने में एक महत्वपूर्ण कदम आगे प्रदान किया है। पूर्ण-पाठ तर्क अनुक्रमों पर निर्भरता को कम करके और असतत अव्यक्त अभ्यावेदन का लाभ उठाकर, शोधकर्ताओं ने एक दृष्टिकोण विकसित किया है जो मॉडल सामान्यीकरण में सुधार करते हुए दक्षता बनाए रखता है। हाइब्रिड संरचना यह सुनिश्चित करती है कि आवश्यक तर्क घटकों को संरक्षित किया जाता है, व्याख्याता और कम्प्यूटेशनल दक्षता को संतुलित करने की चुनौती के लिए एक व्यावहारिक समाधान प्रदान करता है। जैसा कि एलएलएम विकसित करना जारी रखते हैं, इस तरह के तरीके अधिक संसाधन-कुशल कृत्रिम बुद्धिमत्ता प्रणालियों के लिए मार्ग प्रशस्त कर सकते हैं जो उच्च स्तर के तर्क क्षमता को बनाए रखते हैं।
चेक आउट तकनीकी विवरण। इस शोध के लिए सभी श्रेय इस परियोजना के शोधकर्ताओं को जाते हैं। इसके अलावा, हमें फॉलो करने के लिए स्वतंत्र महसूस करें ट्विटर और हमारे साथ जुड़ने के लिए मत भूलना 80K+ एमएल सब्रेडिट।
निखिल मार्कटेकपोस्ट में एक प्रशिक्षु सलाहकार है। वह भारतीय प्रौद्योगिकी संस्थान, खड़गपुर में सामग्रियों में एक एकीकृत दोहरी डिग्री का पीछा कर रहा है। निखिल एक एआई/एमएल उत्साही है जो हमेशा बायोमैटेरियल्स और बायोमेडिकल साइंस जैसे क्षेत्रों में अनुप्रयोगों पर शोध कर रहा है। भौतिक विज्ञान में एक मजबूत पृष्ठभूमि के साथ, वह नई प्रगति की खोज कर रहा है और योगदान करने के अवसर पैदा कर रहा है।